19-10-17-数据采集方法(数据分析与挖掘)
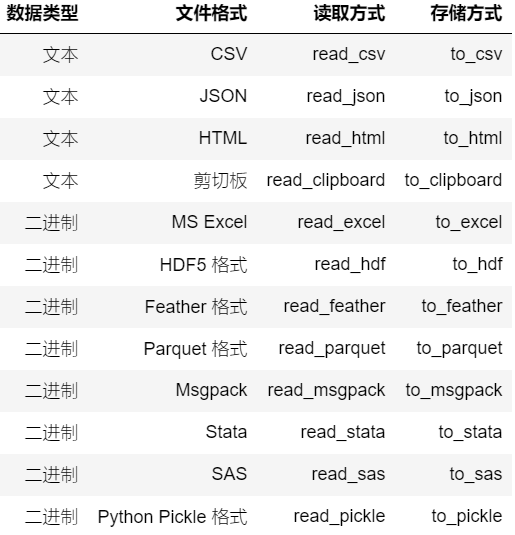
常见数据文件存储和读取
- 数据文件类型
- 数据文件读取
- 数据文件存储
- JSON 解析
- 数据分块读取
常用数据文件格式
当我们使用 Python 读取数据文件时,首先推荐的就是通过 Pandas 完成,Pandas 几乎支持所有常见的数据文件格式。
Excel和CSV格式
由于 Excel 表格有最大的行数储存限制(16,384 列 × 1,048,576 行),所以更多时候我们会使用 CSV 来储存表格数据。
CSV 的英文是 Comma-Separated Values,其实就是通过字符分割数据并以纯文本形式存储。这里的分割字符我们一般会使用逗号,所以往往也称 CSV 文件为逗号分隔符文件。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据,也没有最大行数的储存限制。
我们尝试读取 Excel 和 CSV 格式的示例数据文件。首先,我们需要生成不同类型的数据示例文件。下面这段代码直接点击运行即可,将会在目录下方生成两个最常用的数据文件 test.csv 和 test.xlsx。
import numpy as np
import pandas as pd
# 生成示例数据
df = pd.DataFrame({'A': np.random.randn(10), 'B': np.random.randn(10)})
# 写入数据文件
df.to_csv('test.csv', index=None) # CSV
df.to_excel('test.xlsx', index=None) # EXCEL
print("*****示例文件写入成功*****")
当你读取 Excel 文件时,首先需要安装 openpyxl 模块,不然就会报错。安装该模块的命令为:pip install openpyxl。
使用 Pandas 读取文件的方法,直接运用上面表格中的 API 即可。CSV 文件读取是 read_csv ,而 Excel 文件读取是 read_excel
pd.read_csv("test.csv")
pd.read_excel('test.xlsx')
HDF5 格式
HDF(英语:Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件。HDF5 格式的特点在于能存储多个数据集,并且支持 metadata。
HDF5 文件包含两种基本数据对象:
- 群组(group):类似文件夹,可以包含多个数据集或下级群组。
- 数据集(dataset):数据内容,可以是多维数组,也可以是更复杂的数据类型。
群组和数据集都支持元数据 metadata,用户可以自定义其属性,提供附加信息。元数据类似于「数据的数据」,它能够用来说明数据的特征和其他属性。
HDF5 的好处在于,你不仅可以使用 Python 存储和读取,目前还被 Java,MATLAB/Scilab,Octave,IDL,Julia, R 等语言或商业软件支持。
下面,我们同样尝试使用 Pandas 来存储和读取 HDF5 数据。和 Excel 文件读取相似,我们需要先安装一个依赖模块 PyTables,命令为:pip install tables。
df1 = pd.DataFrame({'A': np.random.randn(10), 'B': np.random.randn(10)}) # 随机数据
df2 = pd.DataFrame({'C': np.random.randn(10), 'D': np.random.randn(10)}) # 随机数据
df1.to_hdf('test.h5', key='df1') # 存储 df1
df2.to_hdf('test.h5', key='df2', format='table') # 存储 df2
"""
会发现上面我们在存储示例数据时,df2 后面指定了 format='table' 参数。这是因为,HDF 支持两种存储架构:fixed 和 table。默认为 fixed,因为其读取速度更快,但是 table 却支持查询操作。
"""
我们通过指定 key 向 HDF 文件中存储了 2 个不同的数据集 df1 和 df2。那么,接下来我们尝试读取。
pd.read_hdf('test.h5', key='df1') # 读取 df1
pd.read_hdf('test.h5', key='df2', where=['index < 5']) # 读取 df2 中 index < 5 的数据
HDF5 既然支持存储多个数据集,是不是类似于数据库中的「表」呢?值得注意的是,HDF5 并不是数据库,如果多个使用者同时写入数据,数据文件会遭到破坏。
JSON 格式
JSON 数据格式与语言无关,脱胎于 JavaScript,但目前很多编程语言都支持 JSON 格式数据的生成和解析。JSON 的官方 MIME 类型是
application/json,文件扩展名是.json。这里特别说到 JSON 格式,原因是其已经成为了 HTTP 请求过程中的标准数据格式。而后面的采集数据过程中,我们会学习到通过 API 请求数据,一般都会对 JSON 进行解析。所以,这里先行了解学习。
JSON 数据中 key 必须是字符串类型,缺失值用 null 表示。其中还可能包含的基本类型有:字典,列表,字符串,数值,布尔值等。
DataFrame 的确是最佳的数据呈现格式。不过,由于 JSON 支持复杂的嵌套,有时候直接通过 read_json 读取到的 DataFrame 并不是我们想要的样子,例如某个键值是以字典或列表存在。此时,我们就会用其他的工具来解析 JSON 了。
Python 中有许多能够储存和解析 JSON 的库,这里推荐使用内建库 json。
json.loads(obj):将json文件中的字符串转化为Python 的数据类型(Python Object)json.dumps可以把 Python Object 转换为 JSON 类型
read_ 操作参数详解
path:路径不仅仅可以读取本地文件,还支持远程 URL 链接。sep:支持按特定字符分割。header:可以指定某一行为列名,默认是第一行。names:自定义列名。skiprows:指定忽略某些行。na_values:对空值进行指定替换操作。parse_dates:尝试将数据解析为日期。nrows:读取指定行数的数据。chunksize:指定分块读取数据大小。encoding:指定文件编码。
如果你的 CSV 文件是使用分号
;而不是逗号,分割,那么就可以通过sep=';'让数据加载为正常的 DataFrame 格式。
像
skiprows非常常用,它可以指定忽略某些行。,使得在加载数据时就可以对数据实现过滤,面对庞大且加载较慢的数据文件时特别好用
分块读取数据
在很多时候,手中的数据集都非常大。例如当我们直接读取一个 GB 级别的 CSV 文件时,不仅速度很慢,还有可能因为内存不足而报错。此时,通过分块读取的方式加载数据文件就非常方便了。
通过上面的 read_ 参数可以看出,分块读取需要指定 chunksize,也就是每一块的大小
chunker = pd.read_csv("test.csv", chunksize=2)
chunker
'''
chunker 返回的 pandas.io.parsers.TextFileReader 是一个可迭代对象。你可以通过 get_chunk() 逐次返回每一个块状数据的内容。你可以尝试多次运行下方单元格,以查看每次迭代的结果。
'''
chunker.get_chunk() #每次只读2行数据
分块读取是解决大文件读取慢的有效手段,但需要注意 chunksize 并不是 Pandas 中每个 read_ 操作都支持的参数,这需要你在使用时通过官方文档确认。
另外,分块读取也不适宜用于解决读取部分数据的需求。例如,你需要读取某个数据的前 1 万条,应该直接使用切片,而非分块读取。当然,如果数据文件本身非常大,全部读取后切片会爆掉内存,此时才宜用分块读取进行解决。
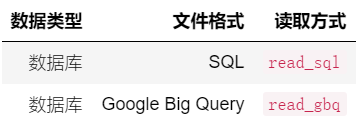
SQL和NoSQL数据库基础
- 数据库连接
- 操作 SQLite 数据库
- SQL 语法介绍
- MongoDB 数据库介绍
- 对 MongoDB 数据库的增删改查
除了数据文件,另外一种读取数据的途径就是直接连接数据库。Pandas 也支持直接连接 SQL 数据库以及 Google Big Query。SQL 数据库就是常见的关系型数据库,例如 MySQL,SQLite 等。而 BigQuery 是 Google 推出的可扩展性强、成本低廉的无服务器企业数据仓库,可让您的所有数据分析人员更加高效地工作。关于 BigQuery 的更多信息 BigQuery 官网
当我们连接数据库时,首先需要安装相应数据库的驱动程序库。例如 MySQL 需要安装 pymysql。由于 SQLite 是 Python 的标准库,所以下面我们通过 SQLite 来学习如何连接数据库。
SQLite 数据库
SQLite 是一个非常常用的关系型数据库。SQLite 具有很多优点,其中最突出的就是无需服务器、也无需配置。SQLite 是非常小且非常轻量,无需外部依赖,非常好用。
SQLite 是数据分析过程中非常推荐的数据库,当你需要备份或分享数据时,无需导入导出,直接将 SQLite 存储的 .sqlite 文件拷贝即可。
因为 SQLite 是 Python 标准库,只需要
import sqlite3即可加载 SQLite 官方文档sqlite3.connect操作连接数据库,指定数据库名称之后,SQLite 会连接或创建相应的数据库文件接下来,我们就可以向
test.sqlite中写入数据了。直接使用 Pandas 中的to_sql即可
import os
import sqlite3
import pandas as pd
import numpy as np
# 如果目录下已存在 SQLite 数据库,执行删除避免重复运行报错
if os.path.exists('test.sqlite'):
os.remove('test.sqlite')
sql_con = sqlite3.connect('test.sqlite') # 连接数据库
# 生成示例数据
df = pd.DataFrame({'A': np.random.randn(50), 'B': np.random.randn(50)})
# 向数据库中写入示例数据,表名为 test_table
df.to_sql(name='test_table', con=sql_con, index=None)
sql_con.close() # 关闭连接
'''
值得注意的是,如果你重复运行上面的单元格会报错,原因是名为 test_table 数据表已经存在了。那么,你可以更改表的名字再写入数据即可。
'''
接下来,我们尝试通过 Pandas 来加载数据库中的数据。这个过程大致分为两个步骤,建立数据库连接,再使用 SQL 语句查询。
sql_con = sqlite3.connect('test.sqlite') # 建立数据库连接
sql_query = "SELECT * FROM test_table" # SQL 查询语句,查询 test_table 表中全部数据
pd.read_sql(sql_query, sql_con) # 执行查询并输出数据
SQL SELECT 语法
详见:Mysql基础课程
MongoDB 数据库

MongoDB 是非常流行的 NoSQL 数据库,支持自动化的水平扩展,同时也被称为文档数据库,因为数据按文档的形式进行存储(BSON 对象,类似于 JSON)。在 MongoDB 中数据存储的组织方式主要分为四级:
- 数据库实例,比如一个 app 使用一个数据库;
- collection 文档集合 ,一个数据库包含多个文档集合,类似于 MySQL 中的表;
- document 文档,一个文档代表一项数据,类似于 JSON 对象,对应于 MySQL 表中的一条记录;
- 字段:一个文档包含多个字段;
MongoDB 存储的数据可以是无模式的,比如在一个集合中的所有文档不需要有一致的结构。也就是说往同一个表中插入不同的数据时,这些数据之间不必有同样的字段。这和关系型数据库彻底不同,在关系型数据库中创建表时就已经确定了数据项的字段,向其中插入数据时,必须是相同的结构。
当我们使用 Python 操作 MongoDB 时,需要安装 PyMongo。安装命令为 :pip install pymongo
使用 PyMongo 的第一步是创建一个 MongoClient 来运行 MongoDB 实例,这里我们连接本地主机与默认端口号
27017。from pymongo import MongoClient client = MongoClient('localhost', 27017) client -------- MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True)一个 MongoDB 的实例可以操作多个独立的数据库,我们使用 PyMongo 的时候可以通过 MongoClient 的属性来获取不同的数据库。这里,我们来获取
shiyanlou数据库。
db = client.shiyanlou
db
-------
Database(MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True), 'shiyanlou')
- MongoDB 中的集合用来保存一组文档,相当于关系型数据库中的数据表。这里我们获取
shiyanlou_collection。
db.shiyanlou_collection
值得注意的是,上面的例子中,我们获取的
shiyanlou数据库和shiyanlou_collection集合都是延迟创建的,也就是说执行上面的命令实际上不会在 MongoDB 的服务器端进行任何操作,只有当第一个文档插进去的时候,它们才会被创建。
MongoDB 存储的文档记录是一个 BSON 对象,类似于 JSON 对象,由键值对组成。比如一条用户记录:
{ name: "Aiden", age: 30, email: "[email protected]" }每一个文档都有一个
_id字段,该字段是主键,用于唯一的确定一条记录。如果往 MongoDB 中插入数据时没有指定_id字段,那么会自动产生一个_id字段,该字段的类型是 ObjectId,长度是 12 个字节。在 MongoDB 文档的字段支持字符串,数字,时间戳等类型。一个文档最大可以达到 16M, 可以存储相当多的数据。接下来,使用
insert_one()方法往 MongoDB 中插入一条数据:
data = {'name': "Aiden", 'age': 30,
'email': "[email protected]", 'addr': ["CD", "SH"]}
users = db.users # 创建一个users集合,用来保存user文档
users_id = users.insert_one(data).inserted_id
users_id
- 插入第一个文档之后,集合
users就被创建了,我们可以用list_collection_names查看数据库中已经创建好的集合:
db.list_collection_names()
------
['users']
- 接下来,我们向
users集合中插入多条数据,可以使用insert_many方法:
data = [{'name': 'lxttx', 'age': 28, 'email': '[email protected]', 'addr': ['BJ', 'CD']},
{'name': 'jin', 'age': 31, 'email': '[email protected]', 'addr':['GZ', 'SZ']},
{'name': 'akk', 'age': 26, 'email': '[email protected]', 'addr': ['NJ', 'AH']}
]
db.users.insert_many(data)
-----
<pymongo.results.InsertManyResult at 0x7f1cc2eb53c8>
- MongoDB 中最常用的基本操作是
find_one(),这个方法返回查询匹配到的第一个文档,如果没有则返回None
users.find_one() #参数为空,来获取 users 集合中的第一个文档
-----
{'_id': ObjectId('5daab08220e98f003263b302'),
'name': 'Aiden',
'age': 30,
'email': '[email protected]',
'addr': ['CD', 'SH']}
users.find_one({'name': "jin"})
--------
{'_id': ObjectId('5daab37320e98f003263b306'),
'name': 'jin',
'age': 31,
'email': '[email protected]',
'addr': ['GZ', 'SZ']}
- 为了查询多个文档,我们可以使用
find()方法,find()方法返回一个 Cursor 对象,使用这个对象可以遍历所有匹配的文档
for user in users.find():
print(user)
------
{'_id': ObjectId('5daab08220e98f003263b302'), 'name': 'Aiden', 'age': 30, 'email': '[email protected]', 'addr': ['CD', 'SH']}
{'_id': ObjectId('5daab08b20e98f003263b303'), 'name': 'Aiden', 'age': 30, 'email': '[email protected]', 'addr': ['CD', 'SH']}
{'_id': ObjectId('5daab25b20e98f003263b304'), 'name': 'Aiden', 'age': 30, 'email': '[email protected]', 'addr': ['CD', 'SH']}
{'_id': ObjectId('5daab37320e98f003263b305'), 'name': 'lxttx', 'age': 28, 'email': '[email protected]', 'addr': ['BJ', 'CD']}
{'_id': ObjectId('5daab37320e98f003263b306'), 'name': 'jin', 'age': 31, 'email': '[email protected]', 'addr': ['GZ', 'SZ']}
{'_id': ObjectId('5daab37320e98f003263b307'), 'name': 'akk', 'age': 26, 'email': '[email protected]', 'addr': ['NJ', 'AH']}
for user in users.find({'name': "jin"}):
print(user)
----
{'_id': ObjectId('5daab37320e98f003263b306'), 'name': 'jin', 'age': 31, 'email': '[email protected]', 'addr': ['GZ', 'SZ']}
- 更新数据主要通过
db.users.update_one或者db.users.update_many方法,前者更新一条记录,后者更新多条记录
```python
db.users.update_one(filter={'name': "Aiden"}, update={
'$set': {'age': 29, 'addr': ["CD", "SH", "BJ"]}})
```
- 删除数据也非常简单,可以通过
db.users.delete_one或db.users.delete_many方法
```python
db.users.delete_many({'addr': "CD"})
```
estimated_document_count()方法可以使用集合元数据估算此集合中的文档数
HTTP 协议及 API 采集数据
- GET 方法请求数据
- Response 响应分析
- 请求 URL 的构造
- JSON 数据读取
- 开发者工具的使用
HTTP 请求方法
通过 HTTP 协议,就可以基于 TCP/IP 通信来传递数据,包括 HTML 文件(网页),图片文件,查询结果等。一般情况下,数据源网站提供获取数据的 API 都是基于 HTTP 协议运行。

当通过 HTTP 请求采集数据时,数据源肯定不会允许修改或删除数据。所以,我们通常只会用到 GET 方法,用来向指定的资源发出请求,读取相应的数据。
通过 API 采集数据
应用程序接口(Application Programming Interface)
- 按照 API 文档中介绍的 HTTP 请求方法,来获取数据。Python 中,我们通常使用
requests模块建立 HTTP 连接
import requests
# 使用 GET 方法请求数据
raw = requests.get(
'http://api.waqi.info/feed/chengdu/?token=d9c0f3c71143407d61c900d9dbb450489303e7e8')
raw
-------
<Response [200]>
如上所示,我们可以将请求地址和参数组合成一个 URL,然后通过 GET 方法完成请求。一般情况下,请求地址和参数之间通过
?连接,参数与参数之间会通过&连接,当然这里只有token一个参数所以不存在&面返回
Response [200]是 HTTP 请求状态码,即代表连接成功。你可以通过json()属性查看返回的 JSON 数据raw.json() #返回值是对应的python数据类型,不是json字符串!!!展开
{'status': 'ok', 'data': {'aqi': 158, 'idx': 1450, 'attributions': [{'url': 'http://www.schj.gov.cn/', 'name': 'Sichuan Province Environmental Protection Agency (四川省环保重点城市环境空气质量实时监测结果)'}, {'url': 'http://www.cdepb.gov.cn/', 'name': 'Chengdu Environmental Protection Agency (成都市环境监测中心站_成都市环境监测中心站)'}, {'url': 'http://106.37.208.233:20035/emcpublish/', 'name': 'China National Urban air quality real-time publishing platform (全国城市空气质量实时发布平台)'}, {'url': 'https://china.usembassy-china.org.cn/embassy-consulates/chengdu/air-quality-monitor/', 'name': 'U.S. Consulate Chengdu Air Quality Monitor'}, {'url': 'https://waqi.info/', 'name': 'World Air Quality Index Project'}], 'city': {'geo': [30.6250145, 104.0670559], 'name': 'Chengdu (成都)', 'url': 'https://aqicn.org/city/chengdu'}, 'dominentpol': 'pm25', 'iaqi': {'co': {'v': 13}, 'no2': {'v': 32}, 'o3': {'v': 1.3}, 'pm10': {'v': 67}, 'pm25': {'v': 158}, 'so2': {'v': 1.6}, 'w': {'v': 1.5}}, 'time': {'s': '2019-10-20 09:00:00', 'tz': '+08:00', 'v': 1571562000}, 'debug': {'sync': '2019-10-20T10:56:34+09:00'}}}
此时,我们可以直接使用 Pandas 把 JSON 读取为 DataFrame 数据类型。
import pandas as pd pd.DataFrame(raw.json())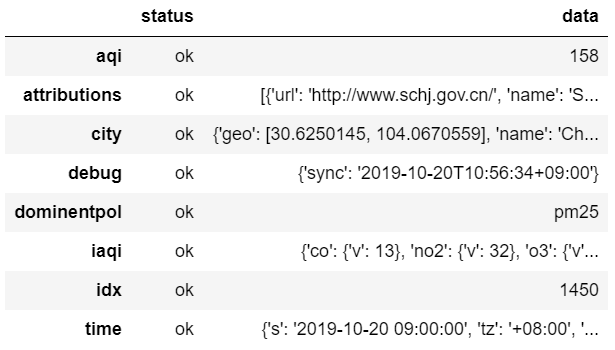
你可能会有疑问,那就是为什么不使用
read_json()读取?如果愿意自己尝试的话,你会发现
pd.read_json(raw.json())会报错。原因是在于,这里的raw.json()返回了 JSON 样式的数据,而数据的类型却为dict,而pd.read_json()只能读取 JSON 数据(字符串类型)。
- 当然,由于源数据嵌套层数较多,直接读取的 DataFrame 并不美观,数据层次展示不清楚。你可以进一步解析 JSON 之后,再转化为 DataFrame。
pd.DataFrame(raw.json()['data']['iaqi'])
获取非公开 API 数据
上面这种情况是网站提供了相应的 API 可供调用,但很多时候你会遇到想采集数据的网站并不会提供 API。此时,也有一些技巧可以更方便地采集数据。
例如,我们想采集实验楼课程的评论数据,然后以实验楼最热门的课程「Linux 基础入门」为例。
首先,我们需要 打开课程页面,这里以 Chrome 浏览器为例。
然后,在页面调出浏览器的「开发者工具」
接下来,切换到开发者工具(DevTools)的网络(Network)面板,刷新页面后就能捕捉到浏览器与服务器之间的全部通信。
然后,在 Filter 导航中选中
XHR选项,用来过滤无关的 HTTP 请求。此时,点击评论「下一页」执行翻页,Network 就能捕获评论数据 JSON。你会发现有一个带 comment 关键词的链接返回了 JSON 格式的数据,并正好对应着评论的内容。你可以把该链接复制下来,即:
https://www.shiyanlou.com/api/v2/comments/?page_size=15&topic_id=1&topic_type=course&cursor=bz0xNQ%3D%3D。你可以发现,此链接和上面请求空气质量指数的 API 链接非常相似,且无需提供token。接下来,我们就可以通过 Python 的
requests模块与该链接建立 HTTP 通信,并获取返回的 JSON 内容。不过,链接中的游标参数cursor控制着页面位置(经验),删除之后就能得到首页的评论。那么,你或许有了新的疑问。我们上面只获取到 15 条评论数据,更多的数据怎么办呢?
如果你仔细观察上面的链接
https://www.shiyanlou.com/api/v2/comments/?page_size=15&topic_id=1&topic_type=course就会发现,链接中有一个page_size=15的参数。其实,API 一般在设计时都是有规律的,你可以将其改为page_size=30试一试
网页数据采集与内容解析
大多数情况下,各类网站为了保护自己的数据不轻易被别人获取,一般都不会轻易提供 API。而在这种情况下,我们拿到网页数据的常用方法就是直接解析页面数据
- Pandas 模块自动解析表格
- 表格数据的文本匹配
- XPath 节点的选择基本规则
- lxml 模块的使用
- BeautifulSoup 模块中 CSS 选择器的使用
- 开发者工具中 XPath 和 CSS 的路径
解析网页表格数据
- 一种快速解析网页表格数据的方法
如果一个网页上存在表格数据,也就是一个以 HTML 标签
<table>标记的表格。那么,使用 Pandas 提供的read_html()是最快解析方法。read_html()会自动提取网页上的表格,并处理成 DataFrame。
import pandas as pd
# 中华人民共和国境内地区邮政编码列表页面
url = "http://labfile.oss.aliyuncs.com/courses/1145/wikipedia_postal_codes.htm"
tables = pd.read_html(url, encoding='utf-8') # utf-8 编码正确显示中文
len(tables) # 页面表单的数量
# 上面得到的结果是 34,即代表页面有 34 个表格
# 接下来,就可以直接输出 DataFrame 的表格内容。
tables[0] # 输出第 1 个表格,索引为 0
#事实上,你可以匹配包含特定文本的表,通过指定 match 参数完成
chengdu = pd.read_html(url, match="成都市", encoding='utf-8') # 查找包含成都市邮政编码的表格
chengdu[0]
XPath解析
XPath (XML Path Language) 是一门路径提取语言,最初被设计用来从 XML 文档中提取部分信息,现在它的这套提取方法也可以用于 HTML 文档上
在使用 XPath 前,大家首先要把几个概念弄明白。首先是
节点(node),以上面的 HTML 文档为例子,每个标签都是一个节点,比如<div class="company"> <h2>腾讯</h2> <img src="tencent.jpg"> <p class="location">深圳</p> </div>- 最外层的
div是整个文档的一个子节点, - 里面包含的公司信息标签都是
div的子节点 - 节点标签之间的内容称为这个节点的文本(text)
- 节点标签内部称为节点的属性(attribute)
- 每个标签都可以有
class属性 (可以有多个对应的值)
- 最外层的
接下来,就可以通过 Python 中的
lxml模块对 HTML 应用 XPath 规则进行节点选择了
from lxml import html
example = """
<!DOCTYPE html>
<html>
<head>
<title>xpath</title>
</head>
<body>
<div class="companies">
<div class="company">
<h2>阿里巴巴</h2>
<a href="alibaba.com"><img src="alibaba.jpg"></a>
<p class="location">杭州</p>
</div>
<div class="company">
<h2>腾讯</h2>
<a href="qq.com"><img src="qq.jpg"></a>
<p class="location">深圳</p>
</div>
<div class="company">
<h2>Facebook</h2>
<a href="facebook.com"><img src="facebook.jpg"></a>
<p class="location">硅谷</p>
</div>
<div class="company">
<h2>微软</h2>
<a href="microsoft.com"><img src="microsoft.jpg"></a>
<p class="location">西雅图</p>
</div>
</div>
</body>
</html>
"""
tree = html.fromstring(example) # 将字符串解析为 HTML Element
tree
- 加载完 HTML 之后,我们说一说节点选择的基本规则:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
# / 表示从根节点开始选取,想要选取 title 节点,就需要按标签的阶级关系来定位
tree.xpath('/html/head/title')
[<Element title at 0x7faf59e75d68>]
# 上面已经获取到 Element title,在选择表达式后面加上 text() 来指定只返回文本
tree.xpath('/html/head/title/text()')
['xpath']
# 而使用 // 就可以不必管标签在文档中的位置
tree.xpath('//title/text()') # 返回网页标题文本
['xpath']
# 当选取到的标签不止一个的时,返回一个列表,如我们选取所有公司的名称所在的 h2 标签
tree.xpath('//h2/text()')
['阿里巴巴', '腾讯', 'Facebook', '微软']
# 要选取属性值,在属性名称前面加上 @ 符号就可以了,如选取所有 img 的 src 属性:
tree.xpath('//img/@src')
['alibaba.jpg', 'qq.jpg', 'facebook.jpg', 'microsoft.jpg']
# 可以用属性来定位节点,如要选取所有 class 属性值为 location 的 p内的文本
tree.xpath('//p[@class="location"]/text()')
['杭州', '深圳', '硅谷', '西雅图']
# 在节点名称后面加上 [n] ,n 是一个数字,可以获取到该节点下某个子节点的第 n 个
# 如要获取 div.companies 下的第二个 div 子 节点,也就是腾讯所在的 div 节点:
tree.xpath('//div[@class="companies"]/div[2]/h2/text()')
['腾讯']
CSS Selector 解析
除了使用 XPath 语法解析 HTML 之外,还有一种常用的方法是使用 CSS Selector 选择。
下面,我们通过 Python 中另一个支持 CSS 选择的模块 Beautiful Soup 进行演示。
from bs4 import BeautifulSoup soup = BeautifulSoup(example, features="lxml") # 加载 HTML # 首先,你可以按层级依次向下选择,直到得到想要的内容。 # 例如,这里我们想得到各个公司的网站地址 soup.select("html body div a[href]") [<a href="alibaba.com"><img src="alibaba.jpg"/></a>, <a href="qq.com"><img src="qq.jpg"/></a>, <a href="facebook.com"><img src="facebook.jpg"/></a>, <a href="microsoft.com"><img src="microsoft.jpg"/></a>] # 此时,如果想要得到最终的地址,需要一个简单的处理过程 for link in soup.select("html body div a[href]"): print(link.get('href')) alibaba.com qq.com facebook.com microsoft.com # 可以通过一些独一无二的标签进行选择 # 如这里公司位置是通过 <p class="location"></p> 标记的,而带有 class="location" 的 p 标签是独一无二的。于是,就可以直接通过该标签解析到数据 soup.select("p.location") [<p class="location">杭州</p>, <p class="location">深圳</p>, <p class="location">硅谷</p>, <p class="location">西雅图</p>] # 同样,如果想要得到最终的内容,需要一个简单的处理过程 for p in soup.select("p.location"): print(p.text) 杭州 深圳 硅谷 西雅图
Chrome 等浏览器的开发者模式提供了一个功能,那就是复制某个标签所在的 XPATH 路径
网络爬虫采集数据的方法
- 构造 CSS 选择器路径
- 获取不同页面的内容
- Scrapy 的安装使用
- Scrapy 提取数据方法
- Scrapy 内置方法
- 正则匹配方法介绍
编写一个简单的爬虫
我们需要先获取 HTML 内容。这里将使用到 requests 和 BeautifulSoup 模块。
我们需要提到 URL 参数的概念。在发送 HTTP 请求时,一般可以附带传递 URL 参数。参数以问号开始并采用
name=value的格式,多个参数以&间隔; 参数和url之间用?间隔。
course_name = []
page_num = 1
for page in range(1,4):
content = requests.get(f"https://www.shiyanlou.com/courses/?page={page}")
soup = BeautifulSoup(content.text, features="lxml")
course_name.extend(soup.select("h6.course-name"))
print("已爬取第{}页面".format(page))
print("*****************")
for name in course_name:
print(name.text.strip())
Scrapy 简介
pip3 install scrapy
Scrapy是使用 Python 实现的一个开源爬虫框架。秉承着「Don’t Repeat Yourself」的原则,Scrapy提供了一套编写爬虫的基础框架和编写过程中常见问题的一些解决方案。
Scrapy 主要拥有下面这些功能和特点:
- 内置数据提取器,支持 XPath 和 CSS Selector 语法,并且支持正则表达式,方便从网页提取信息。
- 交互式的命令行工具,方便测试 Selector 和 debugging 爬虫。
- 支持将数据导出为 JSON,CSV,XML 格式。
- 内置了很多拓展和中间件用于处理:
- cookies 和 session
- HTTP 的压缩,认证,缓存
- robots.txt
- 爬虫深度限制
- 可拓展性强,可运行自己编写的特定功能的插件
Scrapy shell 交互式环境
scrapy shell 提供了一个交互式的 Python 环境方便我们测试和 Debug 爬虫
scrapy shell [url]
需要提供一个网页的 URL,执行命令后,Scrapy 会自动去下载这个 URL 对应的网页,将结果封装为 Scrapy 内部的一个
response对象并注入到 Python shell 中。在这个response对象上,可以直接使用 Scrapy 内置的 CSS 和 XPATH 数据提取器。也就是说,我们无需再像前面解析 HTML 的实验,单独使用 lxml 和 Beautiful Soup 模块了。
由于 Notebook 无法执行可交互的命令,我们通过下面的方法同样可以得到 Scrapy 的 response 对象。
from scrapy.http import TextResponse
r = requests.get("http://doc.scrapy.org/en/latest/_static/selectors-sample1.html")
response = TextResponse(r.url, body=r.text, encoding='utf-8')
response
---------------------
<200 http://doc.scrapy.org/en/latest/_static/selectors-sample1.html>
Scrapy 内置 CSS Selector
CSS Selector 的使用前面已经介绍过了,但 Scrapy 内置的 CSS Selector 方法和 Beautiful Soup 稍有不同
# 要提取例子网页中 ID 为 images 的 div 下所有 a 标签的文本
response.css('div#images a::text').extract()
['Name: My image 1 ',
'Name: My image 2 ',
'Name: My image 3 ',
'Name: My image 4 ',
'Name: My image 5 ']
response.css('div#images a::text').extract_first()
'Name: My image 1 '
response.css('div#images p::text').extract_first(default='默认值')
'默认值'
response.css('div#images a::attr(href)').extract()
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
div#images表示id为images的div- 如果是类名为
images,这里就是div.images - 如果
div中有多个class的情况,用 CSS 提取器可以写为div[class="class1 class2"] div a表示该div下所有a标签::text表示提取文本extract函数执行提取操作,返回一个列表- 如果只想要列表中第一个
a标签下的文本,可以使用extract_first函数 - 任何标签的任意属性都可以用
attr()提取
Scrapy 内置 XPath
同样,XPath 的方法前面也已经学习了,与 Scrapy 内置方法唯一的区别在于,你需要使用 .extract() 才能把内容导出。
response.xpath('/html/head/title/text()').extract()
['Example website']
response.xpath('//*[@id="images"]/a/@href').extract()
['image1.html', 'image2.html', 'image3.html', 'image4.html', 'image5.html']
结合正则表达式
除了 extract() 和 extract_first()方法, 还有 re() 和 re_first() 方法可以用于 css() 或者 xpath() 方法返回的对象。
re()方法中定义的正则表达式会作用到每个提取到的文本中,只保留正则表达式中的子模式匹配到的内容,也就是()内的匹配内容。re_first()方法支持只作用于第一个文本:
response.css('div#images a::text').extract()
['Name: My image 1 ',
'Name: My image 2 ',
'Name: My image 3 ',
'Name: My image 4 ',
'Name: My image 5 ']
response.css('div#images a::text').re('Name: (.+) ')
['My image 1', 'My image 2', 'My image 3', 'My image 4', 'My image 5']
Scrapy 爬虫框架基础实践
- Scrapy Shell 常用命令
- Response 对象的处理
- Pipeline 处理数据
- 数据存取与导出
- 多页面数据爬取
Scrapy 框架简介
Scrapy 是 Python 开发的一个快速、高层次的 WEB 抓取框架,用于抓取 WEB 站点并从页面中提取结构化的数据。Scrapy 用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如 BaseSpider,Sitemap 爬虫等,同时提供了 Web 2.0 爬虫的支持。Scrapy 的架构如下图所示
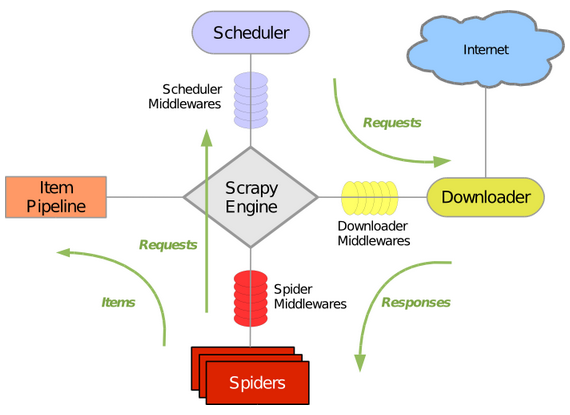
从图中可以看到,Scapy 的组件包括:
- Scrapy Engine:处理系统数据流和事务的引擎。
- Scheduler 和 Scheduler Middlewares:调度引擎发过来的请求。
- Downloader 和 Downloader Middlewares:下载网页内容的下载器。
- Spider :爬虫系统,处理域名解析规则及网页解析。
Scrapy 的基本用法包括下面几个步骤:
- 初始化 Scrapy 项目。
- 实现 Item,用来存储提取信息的容器类。
- 实现 Spider,用来爬取数据的爬虫类。
- 从 HTML 页面中提取数据到 Item。
- 实现 Item Pipeline 来保存 Item 数据。
初始化爬虫项目
根据上面启动 Scrapy 爬虫的流程,我们第一步是先初始化一个爬虫项目。初始化爬虫项目的目的在于减少代码编写工作,因为 Scrapy 会自动为我们生成一个代码目录结构。
创建项目的方法是使用 scrapy startproject 命令,打开终端并执行:
$ scrapy startproject shiyanlou_course
初始化之后,可以看到项目结构是这样的:
└── shiyanlou_course # 部署项目文件夹
├── scrapy.cfg # 部署配置文件
└── shiyanlou_course # 爬虫项目名称
├── __init__.py
├── items.py # 项目 items 定义在这里
├── middlewares.py # 一些下载组件,简单项目无需修改
├── pipelines.py # 项目 pipelines 定义在这里
├── settings.py # 项目配置文件
└── spiders # 所有爬虫写在这个目录下面
└── __init__.py
实现 Item
爬虫的主要目标是从网页中提取结构化的信息,Scrapy 爬虫可以将爬取到的数据作为一个 Python 字典返回,但由于字典的无序性,所以它不太适合存放结构性数据。Scrapy 推荐使用 Item 容器来存放爬取到的数据。
本次实验,我们打算爬取实验楼免费课程的信息,并提取出每门课程的:课程名称、课程介绍、封面图片链接。那么,下面就可以定义这 3 个 Item。
所有的 Item 写在
shiyanlou_course/shiyanlou_course/items.py中,下面为要爬取的课程定义一个Item:
import scrapy
class ShiyanlouCourseItem(scrapy.Item):
"""
定义 Item 非常简单,只需要继承 scrapy.Item 类,将每个要爬取
的数据声明为 scrapy.Field()。下面的代码是我们每个课程要爬取的 3 个数据。
"""
name = scrapy.Field() # 课程名称
description = scrapy.Field() # 课程介绍
image = scrapy.Field() # 课程图片
创建爬虫
定义完 Item 后,就可以开始创建爬虫。
scrapy 的 genspider 命令可以快速初始化一个爬虫模版,使用方法如下:
scrapy genspider <name> <domain>
# name 这个爬虫的名称
# domain 指定要爬取的网站
进入 Scrapy 爬虫所在的 shiyanlou 目录,运行下面的命令快速初始化一个爬虫模版:
cd shiyanlou_course/shiyanlou_course/
scrapy genspider courses shiyanlou.com
scrapy 会在 shiyanlou_course/shiyanlou_course/spiders 目录下新建一个 courses.py 的文件,并且在文件中为我们初始化了代码结构:
import scrapy
class CoursesSpider(scrapy.Spider):
name = 'courses'
allowed_domains = ['shiyanlou.com']
start_urls = ['http://shiyanlou.com/']
def parse(self, response):
pass
allow_domains可以是一个列表或字符串,包含这个爬虫可以爬取的域名。假设我们要爬的页面是https://www.example.com/1.hml, 那么就把example.com添加到 allowed_domains。这个属性是可选的,这里可以保留也可以删除-
start_urls则代表初始爬取的网站页面,我们这里准备爬取的是实验楼免费课程的信息,它的 URL 为:https://www.shiyanlou.com/courses/?fee=free parse()是 Spider 的一个方法。 被调用时,每个初始 URL 完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据,提取数据(生成 Item)以及生成需要进一步处理的 URL 的 Request 对象。parse()作为解析 Response 对象的方法,就要使用的我们前面学习过的 XPATH 或 CSS 选择语法了。
与前面课程学习的内容一致,我们通过浏览器的开发者工具先来分析一下需要获取的数据网源代码,并找到 3 个 Item 对应的 XPATH 路径:
<div
class="col-sm-12 col-md-3"
data-v-7b4a6760=""
data-v-722df677=""
data-v-33421895=""
>
<div class="course-item-box" data-v-7b4a6760="">
<a href="/courses/1" class="link block" data-v-7b4a6760=""
><div class="course-item" data-v-7b4a6760="">
<div class="item-box-top relative" data-v-7b4a6760="">
<div class="course-cover relative" data-v-7b4a6760="">
<img
src="https://dn-simplecloud.shiyanlou.com/ncn1.jpg"
alt="Linux 基础入门(新版)"
class="cover-image"
data-v-7b4a6760=""
/>
</div>
<div class="status-info" data-v-7b4a6760="">
<div class="inner overflow-auto" data-v-7b4a6760="">
<!---->
<span
class="follow-status float-right inline-block text-center color-red"
data-v-7b4a6760=""
><i class="fa fa-star-follow fa-star-o" data-v-7b4a6760=""></i
></span>
</div>
</div>
</div>
<div class="item-box-bottom relative" data-v-7b4a6760="">
<div class="course-info-wrapper relative" data-v-7b4a6760="">
<h6 class="course-name" data-v-7b4a6760="">
Linux 基础入门(新版)
</h6>
<div class="course-description" data-v-7b4a6760="">
要在实验楼愉快地学习,先要熟练地使用 Linux,本实验介绍 Linux
基本操作,shell 环境下的常用命令。
</div>
</div>
<div class="course-meta-data" data-v-7b4a6760="">
<div class="meta-data-inner" data-v-7b4a6760="">
<span class="students-count" data-v-7b4a6760=""
><i class="fa fa-users" data-v-7b4a6760=""></i>
<span data-v-7b4a6760="">229237</span></span
>
<span
class="course-type course-type-tag course-list-tag free"
data-v-7b4a6760=""
>
免费
</span>
</div>
</div>
</div>
</div></a
>
</div>
</div>
那么,根据前面实验学习到的 XPATH 知识,就可以写出 3 个 Item 对应的 XPATH 路径如下:
- 课程名称:
.//h6[@class="course-name"]/text() - 课程介绍:
.//div[@class="course-description"]/text() - 课程图片:
.//img[@class="cover-image"]/@src
接下来,我们就继续编写 courses.py,并从 items 中导入 ShiyanlouCourseItem。同时,将 XPATH 解析出来的数据封装成 item 返回。
import scrapy
from shiyanlou_course.items import ShiyanlouCourseItem
class CoursesSpider(scrapy.Spider):
name = 'courses'
allowed_domains = ['shiyanlou.com']
start_urls = ['https://www.shiyanlou.com/courses/?fee=free']
def parse(self, response):
# 解析当前页面各课程所在的 div, 将返回全部课程 Selector 列表
courses = response.xpath('//div[@class="col-sm-12 col-md-3"]')
# 遍历每个课程, 解析名称, 描述, 图片
for course in courses:
# 按定义好的 Item 结构返回数据
item = ShiyanlouCourseItem()
item['name'] = course.xpath('.//h6[@class="course-name"]/text()').extract_first().strip()
item['description'] = course.xpath('.//div[@class="course-description"]/text()').extract_first().strip()
item['image'] = course.xpath('.//img[@class="cover-image"]/@src').extract_first()
yield item
一般情况下,我们会将同一课程的信息集中返回,所以上面使用了循环结构。
测试爬虫
接下来,我们就可以试运行爬虫了。启动爬虫的方法是进入爬虫部署项目文件夹(scrapy.cfg 文件所在文件夹),然后执行 scrapy crawl 命令,即:
cd shiyanlou_course
scrapy crawl courses
注意,这里执行的是爬虫的名称 scrapy crawl courses,而不是爬虫项目的名称。然后就可以看到 Item 的返回结果,截取一段如下:
2022-01-01 11:11:11 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.shiyanlou.com/courses/?fee=free>
{'description': '要在实验楼愉快地学习,先要熟练地使用 Linux,本实验介绍 Linux 基本操作,shell 环境下的常用命令。',
'image': 'https://dn-simplecloud.shiyanlou.com/ncn1.jpg',
'name': 'Linux 基础入门(新版)'}
2022-01-01 11:11:12 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.shiyanlou.com/courses/?fee=free>
{'description': '本实验主要通过介绍计算机相关技术的基础概念,实验楼的使用方法,面向完全没有编程经验的用户。从中我们将了解到实验楼的实验精神:“从实践切入,依靠交互性、操作性更强的课程,理论学习+动手实践共同激发你的创造力。”',
'image': 'https://dn-simplecloud.shiyanlou.com/ncn63.jpg',
'name': '新手指南之玩转实验楼'}
2022-01-01 11:11:13 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.shiyanlou.com/courses/?fee=free>
{'description': '本课程主要讲解了Python的Django框架的基础知识。通过学习本课程,可以熟悉Django框架的组成结构,并能在学习过程中了解Django的强大功能。',
'image': 'https://dn-simplecloud.shiyanlou.com/course/1531706079197_【1127】-【Django 基础教程】.png',
'name': 'Django 基础教程'}
Item Pipeline 处理数据
如果把 Scrapy 想象成一个产品线,Spider 负责从网页上爬取数据,Item 相当于一个包装盒,对爬取的数据进行标准化包装,然后把他们扔到Pipeline 流水线中。
Pipeline 主要对 Item 进行这几项处理:
- 验证爬取到的数据,检查 Item 是否有特定的 Field。
- 检查数据是否重复。
- 存储到数据库。
当创建项目时,Scrapy 已经在 pipelines.py 中为项目生成了一个 pipline模版:
class ShiyanlouCoursePipeline(object):
def process_item(self, item, spider):
"""
parse 出来的 item 会被传入这里,这里编写的处理代码会
作用到每一个 item 上面。这个方法必须要返回一个 item 对象。
"""
return item
def open_spider(self, spider):
""" 当爬虫被开启的时候调用
"""
pass
def close_spider(self, spider):
""" 当爬虫被关闭的时候调用
"""
pass
如果我们使用数据库存储数据,那么一般就把建立数据库链接写在 open_spider 中,而当爬取完数据后,就执行 close_spider 里面的关闭数据库链接。
存储为数据文件
例如,我们这里打算把爬取到的数据存入为 .csv 文件中,就可以借助于 Pandas 模块来修改 pipelines.py。
修改 pipelines.py 如下:
import pandas as pd
class ShiyanlouCoursePipeline(object):
# 爬虫工作时
def process_item(self, item, spider):
# 读取 item 数据
name = item['name']
description = item['description']
image = item['image']
# 每条数据组成临时 df_temp
df_temp = pd.DataFrame([[name, description, image]], columns=['name', 'description', 'image'])
# 将 df_temp 合并到 df
self.df = self.df.append(df_temp, ignore_index=True)
return item
#当爬虫启动时
def open_spider(self, spider):
# 新建一个带列名的空白 df
self.df = pd.DataFrame(columns=['name', 'description', 'image'])
# 当爬虫关闭时
def close_spider(self, spider):
# 将 df 存储为 csv 文件
pd.DataFrame.to_csv(self.df, "courses.csv")
此时,如果你再次启动爬虫,会发现数据并没有储存到 courses.csv 文件中。原因是 Item Pipeline 默认是未开启状态,需要到 settings.py 文件中自行开启。
要开启 Item Pipeline,需要在 settings.py 将下面的代码取消注释:
# 默认是被注释的
ITEM_PIPELINES = {
'shiyanlou.pipelines.ShiyanlouPipeline': 300
}
ITEM_PIPELINES 里面配置需要开启的 pipeline,它是一个字典,key 表示 pipeline 的位置,值是一个数字,表示的是当开启多个 Pipeline 时它的执行顺序,值小的先执行,这个值通常设在 100~1000 之间。
重新运行爬虫 scrapy crawl courses,courses.csv 文件就会出现在项目文件夹当中了。
爬取多个页面数据
我们刚刚只是爬取了第 1 页的免费课程,那么你可能想要爬取多个页面的数据,最简单的方法是寻找 URL 规律。如果你在上面的页面中点击第 2 页,就能看到 URL 变为了 https://www.shiyanlou.com/courses/?page=2。该 URL 最后的 page=2 实际上就是页码规律。
scrapy.Spider 类已经有了一个默认的 start_requests 方法。那么,只提供需要爬取的 start_urls,默认的 start_requests 方法会根据 start_urls 生成 Request 对象。所以,爬虫 courses.py 代码可以修改为:
import scrapy
from shiyanlou_course.items import ShiyanlouCourseItem
class CoursesSpider(scrapy.Spider):
name = 'multipages'
allowed_domains = ['shiyanlou.com']
start_urls = ['https://www.shiyanlou.com/courses/?fee=free']
# 装饰器
@property
def start_urls(self):
"""
start_urls 需要返回一个可迭代对象,所以,你可以把它写成一个列表、元组或者生成器,这里用的是生成器
"""
url_temp = "https://www.shiyanlou.com/courses/?page={}"
return (url_temp.format(page+1) for page in range(5)) # 1-5 页
def parse(self, response):
# 解析当前页面各课程所在的 div, 将返回全部课程 Selector 列表
courses = response.xpath('//div[@class="col-sm-12 col-md-3"]')
# 遍历每个课程, 解析名称, 描述, 图片
for course in courses:
# 按定义好的 Item 结构返回数据
item = ShiyanlouCourseItem()
item['name'] = course.xpath('.//h6[@class="course-name"]/text()').extract_first().strip()
item['description'] = course.xpath('.//div[@class="course-description"]/text()').extract_first().strip()
item['image'] = course.xpath('.//img[@class="cover-image"]/@src').extract_first()
yield item