Pandas 数据处理基础
知识点
- 数据类型
- 数据读取
- 数据选择
- 数据删减
- 数据填充
数据类型
Pandas 的数据类型主要有以下几种,它们分别是:Series(一维数组),DataFrame(二维数组),Panel(三维数组),Panel4D(四维数组),PanelND(更多维数组)。其中 Series 和 DataFrame 应用的最为广泛,几乎占据了使用频率 90% 以上。
Series
Series 是 Pandas 中最基本的一维数组形式。其可以储存整数、浮点数、字符串等类型的数据。基本结构如下:
pandas.Series(data=None, index=None)
- 其中
data可以是字典,或者NumPy 里的 ndarray 对象等。 index是数据索引,功能是帮助我们更快速地定位数据。
import pandas as pd
s = pd.Series({'a': 10, 'b': 20, 'c': 30})
s
----output----
a 10
b 20
c 30
dtype: int64
'''该 Series 的数据值是 10, 20, 30,索引为 a, b, c,数值类型默认为 int64'''
import numpy as np
s = pd.Series(np.random.randn(5))
s
----output----
0 0.289606
1 0.172003
2 0.741638
3 -1.295529
4 0.445117
dtype: float64
'''用 NumPy 生成的一维随机数组,最终得到的 Series 索引默认从 0 开始,而数值类型为 float64''''
DataFrame
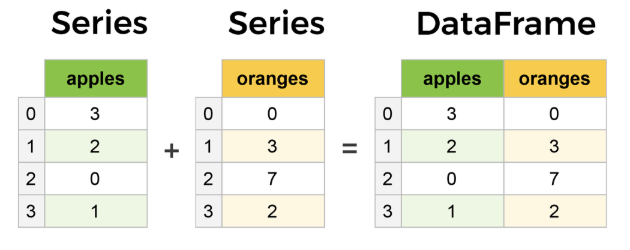
DataFrame 是 Pandas 中最为常见、最重要且使用频率最高的数据结构。DataFrame 和平常的电子表格或 SQL 表结构相似。可以把 DataFrame 看成是 Series 的扩展类型,它仿佛是由多个 Series 拼合而成。它和 Series 的直观区别在于,数据不但具有行索引,且具有列索引。
pandas.DataFrame(data=None, index=None, columns=None)
区别于 Series,其增加了 columns 列索引。DataFrame 可以由以下多个类型的数据构建:
- 一维数组、列表、字典或者 Series 字典。
- 二维或者结构化的
numpy.ndarray。 - 一个 Series 或者另一个 DataFrame。
# 由 Series 组成的字典来构建 DataFrame
df = pd.DataFrame({'one': pd.Series([1, 2, 3]),
'two': pd.Series([4, 5, 6])})
# 也可以直接通过一个列表构成的字典来生成 DataFrame
df = pd.DataFrame({'one': [1, 2, 3],
'two': [4, 5, 6]})
# 由带字典的列表生成 DataFrame ****
df = pd.DataFrame([{'one': 1, 'two': 4},
{'one': 2, 'two': 5},
{'one': 3, 'two': 6}])
# NumPy 的多维数组非常常用,同样可以基于二维数值来构建一个 DataFrame
pd.DataFrame(np.random.randint(5, size=(2, 4)))
# 当不指定索引时,DataFrame 的索引同样是从 0 开始